OR per +1 unit X
–
Exploratory Data Analysis For Epidemiology
This course was developed by Dr. Kiffer G. Card, Faculty of Health Sciences, Simon Fraser University based on Dohoo, I. R., Martin, S. W., & Stryhn, H. (2012). Methods in Epidemiologic Research. VER Inc.
📚 Reference page, available throughout the lesson
This glossary collects the key concepts, people, and ideas you will meet in this lesson. Use it as a reference while you work through the material, or as a review before assessments. Type in the search box to filter entries.
Earlier lessons worked through linear regression for continuous outcomes. This lesson takes the most common alternative in epidemiology: the binary outcome (disease present/absent, vaccinated/unvaccinated, alive/dead). The logistic model was formalised by Cox (1958) and has since become the workhorse logistic regression for dichotomous outcomes in epidemiology. The four content sections walk through this in order: why ordinary linear regression breaks down for binary outcomes and what the logistic model replaces it with (this section), the assumptions and how to test the overall model and individual coefficients (a later section), goodness-of-fit and predictive ability (a later section), and finally extensions including generalised linear models and exact logistic regression for sparse data (a later section). The odds ratios you computed by hand in an earlier course reappear here as exponentiated regression coefficients.
When the outcome variable is dichotomous (e.g., disease present/absent), ordinary linear regression is inappropriate for three fundamental reasons:
Logistic regression solves all three problems by modelling the log odds (logit) of the outcome rather than the probability directly (Cox, 1958). The logit transformation maps probabilities from the bounded range (0, 1) to the entire real number line (−∞, +∞), making it suitable for linear modelling.
The logistic regression model expresses the log odds of the outcome as a linear combination of predictors:
The inverse logit (or logistic function) converts back to the probability scale:
Note that, unlike linear regression, the logistic model has no error term because it models on the logit scale. The randomness enters through the binomial distribution of the outcome.
The odds of the outcome are p / (1 − p). The odds ratio for the kth predictor is obtained by exponentiating its coefficient:
For a dichotomous predictor, this is the odds ratio comparing the group coded 1 to the group coded 0, adjusted for all other variables in the model. Care is needed in interpretation: odds ratios are not risk ratios and can exaggerate the apparent strength of association when the outcome is common (Norton, Dowd, & Maciejewski, 2018).
Take a fitted model for a yes/no outcome with intercept β0 = -1.6 and a single smoking coefficient β1 = 0.69 (smoker = 1, non-smoker = 0). Reading it takes three short steps, and it is worth doing the arithmetic once by hand.
1. Log odds. Add up the linear part. For a non-smoker that is just the intercept, -1.6. For a smoker it is -1.6 + 0.69 = -0.91.
2. Odds, then probability. Exponentiate the log odds to get the odds, then turn odds into a probability with p = odds / (1 + odds). Non-smoker: odds = e-1.6 = 0.20, so p = 0.20 / 1.20 = 0.17. Smoker: odds = e-0.91 = 0.40, so p = 0.40 / 1.40 = 0.29.
3. Odds ratio. The odds ratio for smoking is the ratio of the two odds, 0.40 / 0.20 = 2.0, which is exactly e0.69. This is the same OR = eβ from the formula above, now seen from the raw odds rather than the coefficient.
The example also makes one caution concrete. The risk ratio here is 0.29 / 0.17 = 1.7, noticeably smaller than the odds ratio of 2.0. When the outcome is common, the odds ratio sits further from 1 than the risk ratio, which is why an odds ratio can overstate how much the underlying risk really changes.
Slide the intercept (β₀) and slope (β₁). The linear-in-log-odds world (left) and the nonlinear-in-probability world (right) are two views of the same model. The S-curve’s steepness is set by β₁; its midpoint is set by −β₀/β₁.
Unlike linear regression, which uses least squares, logistic regression uses maximum likelihood estimation (MLE). MLE is an iterative process that finds the parameter values most likely to have produced the observed data. The algorithm starts with initial estimates and refines them until convergence, the point at which the change in the log-likelihood between iterations falls below a specified criterion.
Consider a study of low birth weight (<2500 g) as the outcome. Predictors include the mother’s smoking status, race, and number of prenatal visits. Because the outcome is dichotomous (low birth weight: yes/no), logistic regression is appropriate.
The model would be: ln(p / (1 − p)) = β0 + β1(smoking) + β2(race) + β3(prenatal visits). From the fitted model, eβ1 gives the adjusted odds ratio for smoking, comparing smokers to non-smokers while holding race and prenatal visits constant.
1. What does the logit function transform?
2. In a logistic regression, how is the odds ratio for a dichotomous predictor computed?
3. Why is maximum likelihood estimation (MLE) used instead of least squares for logistic regression?
Think about a dichotomous health outcome in your field. What predictors would you include in a logistic regression model? Why is modelling on the logit scale preferable to modelling the probability directly?
An earlier section set up the model and showed how its coefficients become odds ratios on the exponentiated scale. This section turns to the same questions you asked of linear regression in an earlier lesson: are the assumptions met, is the overall model significant, what do the individual coefficients mean, and how do confounding and interaction enter the picture? Most of the framework is identical; the differences are mostly in how we compute and interpret coefficients on the log-odds scale.
Logistic regression requires two key assumptions: (1) independence of observations, and (2) linearity on the logit scale, that is, the relationship between each continuous predictor and the log odds of the outcome is linear. Note that the relationship on the probability scale will be non-linear (S-shaped).
The likelihood ratio test (LRT) compares the fitted model to the null model (intercept only). The test statistic is:
This statistic follows an approximate chi-squared distribution with degrees of freedom equal to the number of predictors. It can also be used to compare any two nested models (Eq 16.10), a full model versus a reduced model, to test whether the excluded variables contribute significantly.
The Wald test divides the coefficient by its standard error (following a Z distribution) and is more commonly reported by software. However, Wald tests can be unreliable when the true probability is near 0 or 1, or when the sample size is small (Vittinghoff & McCulloch, 2007).
The Wald test can be unreliable when the estimated probability is near the boundary (0 or 1), because the coefficient estimate and its standard error may be poor approximations. In such cases, the likelihood ratio test is preferred as it has better statistical properties.
For a dichotomous predictor (coded 0/1), the coefficient β represents the log odds ratio comparing the group coded 1 to the group coded 0, adjusted for all other variables. The odds ratio is simply OR = eβ. For example, if βsmoking = 0.69, then OR = e0.69 = 2.0, meaning the odds of the outcome are twice as high for smokers compared to non-smokers.
For a continuous predictor, β represents the change in the log odds for each 1-unit increase in the predictor. The OR = eβ gives the multiplicative change in odds per unit increase. To compute the OR for any arbitrary change from x1 to x2:
For example, if βage = 0.04, the OR per 10-year increase in age is e0.04 × 10 = e0.4 = 1.49.
Categorical predictors with more than two levels are represented using indicator (dummy) variables. One category serves as the baseline/reference, and each coefficient represents the log OR comparing that category to the reference. To evaluate the overall significance of the categorical variable, use a multi-degree-of-freedom Wald test or an LRT comparing models with and without the entire set of indicator variables.
The intercept (β0) represents the logit of the probability of the outcome when all predictors equal zero. On the probability scale, this is: p = 1/(1 + e−β0). The intercept is often not substantively meaningful (e.g., if age = 0 is not a plausible value), but it is essential for computing predicted probabilities. Note that effects on the probability scale are non-linear: the same change in a predictor produces different changes in probability depending on the baseline values of all predictors.
The course dataset includes a binary hypertension outcome (Yes/No) we will use here. The full annotated script is in r-activities/HSCI_410_Lesson_5_Logistic_Regression.R; the highlights:
# 0. Load + ensure outcome has the REFERENCE level FIRST ("No")
phaa <- read.csv("phaa_survey_clean.csv", stringsAsFactors = FALSE)
phaa$hypertension <- factor(phaa$hypertension, levels = c("No", "Yes"))
phaa$smoker <- factor(phaa$smoker, levels = c("No", "Yes"))
# 1. Crude (unadjusted) model -----------------------------------------------
glm_1 <- glm(hypertension ~ smoker,
data = phaa,
family = binomial(link = "logit"))
summary(glm_1)
exp(coef(glm_1)) # crude odds ratio
exp(confint(glm_1)) # 95% CI for the OR
# 2. Adjusted (multivariable) model -----------------------------------------
glm_2 <- glm(hypertension ~ smoker + age + gender + bmi + dep_score,
data = phaa,
family = binomial)
summary(glm_2)
or <- exp(coef(glm_2))
ci <- exp(confint(glm_2))
round(cbind(OR = or, ci, p = summary(glm_2)$coef[,"Pr(>|z|)"]), 3)
# 3. Likelihood-ratio test for nested models ---------------------------------
anova(glm_1, glm_2, test = "Chisq")
# 4. Goodness-of-fit and discrimination --------------------------------------
library(generalhoslem); library(DescTools); library(pROC)
logitgof(obs = glm_2$y, fitted(glm_2)) # Hosmer-Lemeshow
PseudoR2(glm_2, which = "all") # McFadden / Nagelkerke
phaa$pred_htn <- predict(glm_2, type = "response")
auc(roc(phaa$hypertension, phaa$pred_htn,
levels = c("No", "Yes")))Read the table. An OR of 2.0 for smokerYes means smokers have twice the odds of hypertension as non-smokers, holding age, gender, BMI, and depression score constant. Confounding check (a later lesson of an earlier course): if the crude OR from glm_1 differs meaningfully from the adjusted OR in glm_2, one or more of the added covariates is confounding the smoking-hypertension relationship.
Use the questions below to interpret the output you produced. Look at your console / plot before answering.
1. From exp(coef(glm_1)) and exp(coef(glm_2)), what are the crude and adjusted odds ratios for smokerYes? By what percent did the OR change after adjustment? Does that change exceed a 10% rule-of-thumb threshold for confounding?
exp(coef(glm_1)) typically gives a crude OR for smokerYes around 1.85, and exp(coef(glm_2)) after adjustment around 1.55, a roughly 16% reduction. That exceeds the 10% rule-of-thumb threshold and signals that one or more measured covariates (age, BMI, sex) was confounding the crude smoking-hypertension association. The interpretation: adjusted smokers have ~55% higher odds of hypertension than non-smokers, accounting for measured confounders, meaningfully smaller than the unadjusted gap but still substantial.2. From the tidied table (round(cbind(OR, ci, p), 3)), which predictors have a 95% CI that excludes 1.0? Pick one and translate its OR into a one-sentence interpretation on the odds scale.
3. Report the Hosmer-Lemeshow p-value, the McFadden pseudo R-squared, and the AUC from the ROC curve. Does the model fit well, and how good is its discrimination between people with and without hypertension?
To assess whether a variable is a confounder, add it to the model and check whether the coefficient of the primary predictor of interest changes substantially. A common rule of thumb is a change of more than 10–20% in the coefficient (or OR). If the coefficient changes meaningfully, the variable should be retained as a confounder regardless of its statistical significance.
Interaction is assessed by adding cross-product terms (e.g., x1 × x2) to the model. When an interaction is present, the odds ratio for one variable varies depending on the level of the interacting variable. For example, if smoking interacts with sex, the OR for smoking would differ between males and females. Test the interaction term using an LRT or Wald test. If significant, the main effects alone are insufficient to describe the relationship. Note that multiplicative interaction on the logit scale does not necessarily imply additive interaction on the risk scale, an important consideration for public-health interpretation (Knol et al., 2008).
1. The likelihood ratio test (LRT) compares models by:
2. For a continuous predictor, what does the odds ratio represent?
3. When assessing confounding in logistic regression, you should:
Imagine you are fitting a logistic regression model for a health outcome. How would you decide whether to report odds ratios per 1-unit increase or per a larger clinically meaningful increment for continuous predictors? Why does this matter for interpretation?
An earlier section covered model construction and interpretation. This section turns to model evaluation: residuals, formal goodness-of-fit tests (Hosmer & Lemeshow, 1980), predictive ability via discrimination (ROC curves; Hanley & McNeil, 1982) and calibration, the question of overdispersion, pseudo-R² statistics, and influential observations. Each gives a different angle on whether the model you've built is actually fit for the question you're asking (Steyerberg et al., 2010).
The model-building process for logistic regression follows the same general principles as for linear regression (Chapter 15): develop a causal diagram, perform unconditional (univariable) analyses, evaluate linearity of continuous predictors on the logit scale, and use automated selection methods with caution. Subject matter knowledge should guide decisions at every step.
A covariate pattern is a unique combination of predictor values. Whether the data are treated as binary (one observation per row) or binomial/grouped (multiple observations per covariate pattern) has implications for how residuals and goodness-of-fit statistics are computed and interpreted.
A commonly used minimum sample size guideline for logistic regression is at least 10(k + 1) positive outcomes, where k is the number of predictors. For example, if you have 5 predictors, you need at least 10(5 + 1) = 60 positive outcomes (events). Having fewer events can lead to unreliable coefficient estimates and model instability, though simulation work has shown this rule can be relaxed in some scenarios (Vittinghoff & McCulloch, 2007).
Pearson residuals and deviance residuals are used to assess model fit at the level of individual covariate patterns (Eq 16.16). Both types compare observed outcomes to predicted probabilities, but they differ in how discrepancies are scaled. These residuals are the building blocks of several goodness-of-fit tests.
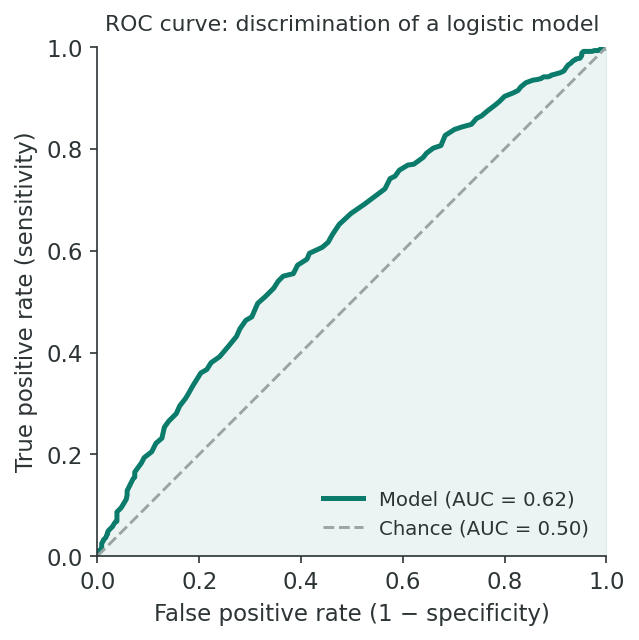
Discrimination is most often summarised by the area under the receiver operating characteristic (ROC) curve (Hanley & McNeil, 1982), while calibration assesses agreement between predicted and observed risks (Steyerberg et al., 2010).
| Concept | Definition | Also Known As |
|---|---|---|
| Sensitivity | Proportion of true positives correctly identified by the model | True positive rate |
| Specificity | Proportion of true negatives correctly identified by the model | True negative rate |
| Cutpoint | The predicted probability threshold above which subjects are classified as positive | Classification threshold |
Selecting a cutpoint involves a trade-off between sensitivity and specificity. A lower cutpoint increases sensitivity but decreases specificity, and vice versa. The ROC curve provides a visual summary of this trade-off across all possible cutpoints.
Apparent overdispersion occurs when the Pearson χ² statistic is inflated, not because of true extra-binomial variation, but because there are many covariate patterns with very few observations each. This is especially common in binary data with continuous predictors. The Hosmer-Lemeshow test is more appropriate in this situation.
Real overdispersion occurs when there is more variability in the data than the binomial model predicts. A common cause is clustering of observations, for example patients within the same hospital may have correlated outcomes. Real overdispersion can be addressed by adjusting standard errors using a dispersion parameter or by using models that account for clustering (e.g., GEE, mixed models).
Overdispersion can be detected when the ratio of the Pearson χ² (or deviance) to its degrees of freedom substantially exceeds 1. For grouped data, this ratio should be close to 1 if the model fits well. Values much greater than 1 suggest overdispersion, while values much less than 1 may suggest underdispersion or a model that is too complex.
Pseudo-R² measures (e.g., McFadden’s, Cox-Snell, Nagelkerke) provide an indication of how much of the variation in the outcome is explained by the model. They are analogues of R² in linear regression but are not directly comparable. Values tend to be lower for logistic regression than for linear regression.
Influential observations can be identified using several diagnostic measures: outliers (large residuals), leverage (unusual covariate patterns), delta-betas (influence on individual coefficients), delta-χ², and delta-deviance (influence on overall fit). These diagnostics help identify observations that disproportionately affect the model.
Returning to the low birth weight example, suppose the fitted model has an AUC of 0.623. This indicates limited predictive ability: the model does only marginally better than chance at discriminating between low and normal birth weight infants. This does not necessarily mean the model is useless for understanding risk factors; it simply means the included predictors explain only a small portion of the variation in birth weight outcomes.
1. What does the Hosmer-Lemeshow test evaluate?
2. What does an ROC curve AUC of 0.5 indicate?
3. The minimum sample size rule for logistic regression suggests:
Consider a logistic regression model you have encountered (or might build). How would you evaluate whether the model has adequate goodness of fit and predictive ability? Which diagnostics would be most important to check?
Earlier sections covered standard logistic regression. This section places it in a wider context. Logistic regression is one example of the generalised linear model (GLM) family, which also includes the linear, Poisson, and other regressions you'll meet later in this course. The section closes with exact logistic regression, the small-sample alternative when standard maximum-likelihood methods fail.
Logistic regression is a member of the broader family of Generalised Linear Models (GLMs). A GLM is defined by two key components: (1) a link function that relates the expected value of the outcome to the linear combination of predictors, and (2) the distribution of the outcome variable.
| Data Type | Distribution | Canonical Link | Example |
|---|---|---|---|
| Continuous | Gaussian (Normal) | Identity | Linear regression |
| Binary | Binomial | Logit | Logistic regression |
| Count | Poisson | Log | Poisson regression |
| Count (overdispersed) | Negative Binomial | Log | NB regression |
The canonical link is the “natural” link function for each distribution. For binary data, the canonical link is the logit. Non-canonical links (e.g., probit, complementary log-log for binary data) can also be used. GLMs are estimated using maximum likelihood, often with iterative algorithms such as Newton-Raphson or iteratively reweighted least squares. Quasi-likelihood estimation can be used when the full distribution is not specified, requiring only the mean-variance relationship.
Standard logistic regression relies on large-sample approximations. When the dataset is very small or severely unbalanced (e.g., very few events), these approximations may be poor, and ML estimates can be biased or fail to converge. Exact logistic regression uses conditional maximum likelihood to produce exact P-values and confidence intervals without relying on large-sample theory. A widely used alternative is the penalised-likelihood approach of Firth (1993), which reduces small-sample bias and handles separation gracefully.
Exact logistic regression is preferred when:
The trade-off is that exact methods are computationally intensive and may not be feasible for models with many predictors.
Conditional logistic regression is used for matched case-control studies. In matched designs, using unconditional logistic regression with stratum (matched set) indicators is problematic because: (1) the number of parameters grows with the number of matched sets, and (2) coefficient estimates can be biased, especially with small strata.
Conditional logistic regression solves this by using a conditional likelihood (Eq 16.17) that eliminates the stratum-specific intercept parameters from the estimation. This produces unbiased estimates of the odds ratios for the predictors of interest without needing to estimate the matching parameters.
Conditional logistic regression has several limitations:
Standard logistic regression: Use when the sample size is adequate, events are not extremely rare, and data are not matched.<br>Exact logistic regression: Use when the sample is very small, data are severely unbalanced, or perfect prediction occurs.<br>Conditional logistic regression: Use for matched case-control studies where stratum-specific parameters would be problematic to estimate.
1. In the GLM framework, what are the two key components that must be specified?
2. When is exact logistic regression preferred over standard logistic regression?
3. In conditional logistic regression for matched data, why is the intercept not estimated?
Think about a study design in your field that uses matching (e.g., matched case-control). Why would conditional logistic regression be more appropriate than unconditional logistic regression for analysing such data? What information would be lost by using the conditional approach?
This lesson took the binary outcome, the most common outcome in epidemiology, and built a regression framework around it, building on the foundational work of David Cox; Cox, 1958). We started by showing why ordinary linear regression breaks for dichotomous data and how the logit transformation rescues us, then moved through coefficient interpretation as adjusted odds ratios, the assumption of linearity on the logit scale, and the likelihood-ratio and Wald tests for inference. An earlier section broadened the lens from estimation to evaluation: residuals, Hosmer–Lemeshow, ROC curves, calibration, pseudo-R², and overdispersion give complementary views of whether a fitted model is actually fit for purpose.
An earlier section placed logistic regression inside the wider GLM family and flagged the small-sample escape hatches: exact logistic regression for sparse data and perfect prediction, and conditional logistic regression for matched case-control studies. With those pieces in place you have the binary toolbox you'll keep using for the rest of the course: every later model in this course (ordinal, multinomial, Poisson, Cox) is a variation on the same maximum-likelihood theme you have just learned.
The final assessment asks you to move fluently between the log-odds scale and the odds-ratio scale, and to choose appropriate diagnostics for a model someone hands you. Treat the questions like a code review of your own analytic habits.
Now that you have completed all four sections, summarise the key concepts of logistic regression. How does it differ from linear regression, what are the main tools for evaluating model fit, and when would you choose conditional or exact logistic regression over the standard approach?
1. Why can’t linear regression be used for dichotomous outcomes?
2. The logit function transforms probability to:
3. In logistic regression, OR = eβ1 represents:
4. Maximum likelihood estimation finds parameter values that:
5. The LRT statistic G²0 follows approximately a:
6. Why is the Wald test sometimes unreliable?
7. For a continuous predictor, the OR for a change from x1 to x2 is:
8. Coefficients for categorical predictors represent effects compared to:
9. The intercept in a logistic model represents:
10. The Pearson χ² goodness-of-fit test requires:
11. An ROC curve that closely follows the 45° diagonal indicates:
12. Overdispersion in logistic regression can be caused by:
13. In the GLM framework, the canonical link for binary data is:
14. Conditional logistic regression is used for:
15. A limitation of conditional logistic regression is:
✦ Before submitting: pass every section knowledge check (100%) and complete every reflection.