Data Cleaning &
Descriptive Analyses
Exploratory Data Analysis For Epidemiology
Learning objectives for this lesson:
- Identify common types of data errors and their sources in the data pipeline
- Distinguish between missing data mechanisms (MCAR, MAR, MNAR) and their analytic implications
- Apply systematic data cleaning strategies including range checks, outlier detection, and consistency verification
- Select and implement appropriate methods for handling missing data
- Calculate and interpret measures of central tendency, spread, and shape
- Construct and interpret descriptive summaries appropriate for epidemiologic research
- Assess distributional assumptions and select appropriate visualization techniques
This course was developed by Dr. Kiffer G. Card, Faculty of Health Sciences, Simon Fraser University based on Dohoo, I. R., Martin, S. W., & Stryhn, H. (2012). Methods in Epidemiologic Research. VER Inc.
Glossary: Key Terms, People & Concepts
📚 Reference page, available throughout the lesson
This glossary collects the key concepts, people, and ideas you will meet in this lesson. Use it as a reference while you work through the material, or as a review before assessments. Type in the search box to filter entries.
Data Quality & Types of Errors
Introduction and Overview
An earlier lesson set up the structured workflow that takes raw data from collection to analysis-ready files. This lesson zooms into two specific phases of that pipeline that deserve their own treatment: cleaning the data (detecting errors, handling missing values, deciding how to deal with outliers) and producing descriptive analyses (the numerical summaries and visualisations that every analysis report eventually needs). The three content sections walk through this in order: data quality and types of error (this section), the cleaning workflow itself (a later section), and descriptive statistics and Table 1 (a later section).
Learning Objectives
- Trace where errors enter the collection → entry → storage → analysis pipeline.
- Distinguish between common error types (random vs. systematic, structural vs. value-level).
- Classify missing-data mechanisms (MCAR, MAR, MNAR) and explain why the distinction matters.
- Describe variable types in epidemiologic data and the operations each type supports.
The Data Pipeline
Before any statistical analysis can begin, data must travel through a pipeline: collection → entry → storage → analysis. Errors can be introduced at every stage, and understanding where problems arise is the first step toward ensuring high-quality data for epidemiologic research.
Key Principle
The quality of your analysis can never exceed the quality of your data. Careful attention to data quality at each stage of the pipeline is a prerequisite for valid epidemiologic inference. Data quality is multidimensional, going beyond accuracy to include completeness, timeliness, consistency, and relevance to the user (Wang & Strong, 1996).
At the collection stage, errors may arise from poorly worded survey items, interviewer bias, instrument malfunction, or participant misunderstanding. During data entry, transcription mistakes and coding errors are common. Storage introduces risks of data corruption, version control problems, and format incompatibilities. Finally, at the analysis stage, incorrect variable coding, inappropriate transformations, and software errors can compromise results.
Types of Data Errors
Errors in epidemiologic datasets take many forms. Van den Broeck, Argeseanu Cunningham, Eeckels, & Herbst (2005) describe data cleaning as a three-stage process, screening, diagnosing, and editing, that should be planned into study design rather than improvised after collection. Click each card below to learn about common error types.
Missing Data
Missing data are ubiquitous in epidemiologic research. The mechanism by which data become missing has profound implications for the validity of subsequent analyses. Rubin (1976) identified three missing data mechanisms:
Important Warning
The missing data mechanism is an assumption that cannot be verified from the observed data alone. You should always conduct sensitivity analyses to assess how your results might change under different assumptions about the missing data mechanism.
Data Dictionaries and Codebooks
A data dictionary (or codebook) is a structured document that describes every variable in a dataset: its name, label, type, valid range, coding scheme, and source. Maintaining a comprehensive data dictionary is essential for:
- Ensuring consistency across data entry operators
- Facilitating communication among research team members
- Supporting reproducibility when analyses are revisited months or years later
- Identifying and resolving coding discrepancies
Variable Types in Epidemiologic Data
Correctly classifying variables is fundamental to choosing appropriate cleaning strategies and analytic methods.
1. A researcher discovers that a participant’s recorded date of diagnosis is earlier than their date of birth. What type of error is this?
2. Under which missing data mechanism can complete-case analysis still produce unbiased estimates?
3. Which of the following is NOT a primary purpose of a data dictionary?
● Complete the knowledge check to continue.
Data Cleaning Strategies
Introduction and Overview
An earlier section named the kinds of errors that can enter a dataset. This section provides the cleaning workflow that addresses them: systematic verification, outlier identification, missing-data handling, transformations, recoding, and string cleaning. Each step has its own techniques and its own decisions to document.
Learning Objectives
- Run range, type, and consistency checks as a first systematic verification pass.
- Identify outliers and decide whether to keep, transform, or exclude them, with reasons recorded.
- Choose an appropriate missing-data strategy (complete-case, single imputation, multiple imputation) given the mechanism.
- Apply transformations and derive new variables without losing the audit trail back to the raw data.
- Document every cleaning decision so that another analyst could reproduce your final dataset.
Systematic Verification
Data cleaning should follow a systematic, documented process. The goal is not to “fix” data arbitrarily but to identify and resolve genuine errors while preserving the integrity of valid observations.
Range checks verify that values fall within predefined valid or plausible bounds. For example, gestational age should be between approximately 20 and 44 weeks; human body temperature typically ranges from 35°C to 42°C.
Define both hard limits (biologically impossible values that should be flagged as errors) and soft limits (unusual but possible values that should be reviewed).
Consistency checks examine whether values across multiple fields are logically compatible. Examples include verifying that discharge dates occur after admission dates, that a participant’s age is consistent with their reported date of birth, and that skip patterns in questionnaires are respected.
These checks often require domain knowledge about the relationships between variables.
Cross-validation involves comparing data from multiple sources to verify accuracy. For example, comparing self-reported medication use with pharmacy dispensing records, or verifying diagnoses against medical chart reviews.
When discrepancies arise, establishing a hierarchy of data source reliability is essential for deciding which value to retain.
Identifying Outliers
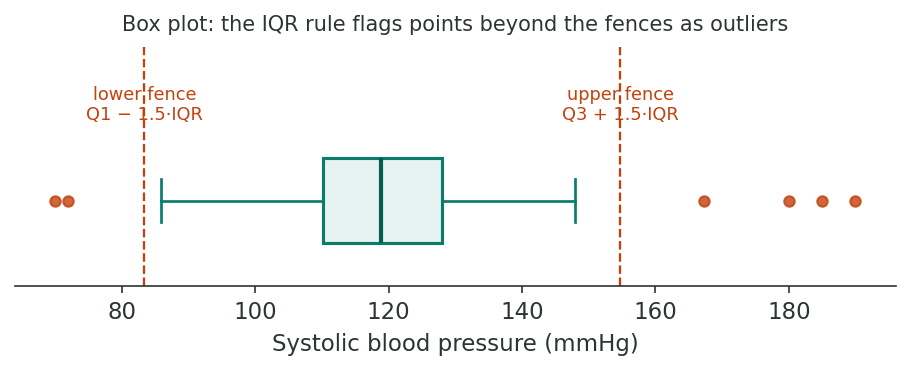
Outliers are observations that lie far from the bulk of the data. They may represent genuine extreme values, data errors, or observations from a different population. The visual tools used to spot them, including box plots, stem-and-leaf displays, and the broader practice of looking at data before modelling, trace back to Tukey (1977). Several methods are used to identify them:
The interquartile range (IQR) method defines outliers as values falling below Q1 − 1.5×IQR or above Q3 + 1.5×IQR, where Q1 and Q3 are the 25th and 75th percentiles, respectively.
This method is robust to extreme values because it is based on percentiles rather than the mean and standard deviation. Values beyond 3×IQR from the quartiles are sometimes termed “extreme outliers.”
The z-score method standardizes each observation as z = (x − mean) / SD. Values with |z| > 3 are commonly flagged as potential outliers.
This approach assumes an approximately normal distribution and can be misleading for heavily skewed data because the mean and SD are themselves influenced by outliers (the masking effect).
Visual inspection using boxplots, histograms, and scatterplots is often the most informative first step in outlier detection.
- Boxplots display the median, IQR, and individual outliers beyond the whiskers
- Histograms reveal gaps in the distribution that may indicate erroneous values
- Scatterplots can reveal bivariate outliers that appear normal when each variable is examined individually
Visual methods should complement, not replace, quantitative rules. Always investigate outliers before deciding to exclude them.
Practical Tip
Never delete an outlier simply because it is extreme. Investigate whether it represents a data error, a genuinely unusual observation, or a member of a different subpopulation. Document every decision to retain or remove an outlier in your audit trail.
Handling Missing Data
The choice of method for handling missing data depends on the assumed missing data mechanism and the proportion of missingness. Practical guidance on implementing multiple imputation via chained equations, including how to specify the imputation model, how many imputations to draw, and how to diagnose problems, is given by White, Royston, & Wood (2011).
Excludes any observation with one or more missing values. Simple to implement, but can dramatically reduce sample size and introduces bias unless data are MCAR. In multivariable models with many variables, even low rates of missingness on individual variables can lead to large cumulative losses.
Uses all available data for each analysis. For example, when computing a correlation matrix, each pair of variables uses all cases with non-missing values for that pair. This preserves more data than listwise deletion, but can produce inconsistent results (e.g., a correlation matrix that is not positive semi-definite).
Mean imputation replaces missing values with the variable mean. While simple, it underestimates variance and distorts relationships between variables. Median imputation is more robust for skewed distributions. Mode imputation is used for categorical variables.
All single imputation methods treat the imputed value as if it were known with certainty, leading to underestimated standard errors and overly narrow confidence intervals.
Multiple imputation creates several (typically 5–20) plausible imputed datasets, analyzes each separately, and pools the results using Rubin’s rules. This approach correctly accounts for the uncertainty due to missing data and produces valid inference under the MAR assumption.
Multiple imputation is currently considered the gold standard for handling missing data in epidemiologic research when the proportion of missingness is non-trivial (Sterne et al., 2009).
Data Transformations
When continuous variables are heavily skewed, transformations can make the distribution more symmetric, stabilize variance, and improve the validity of parametric methods.
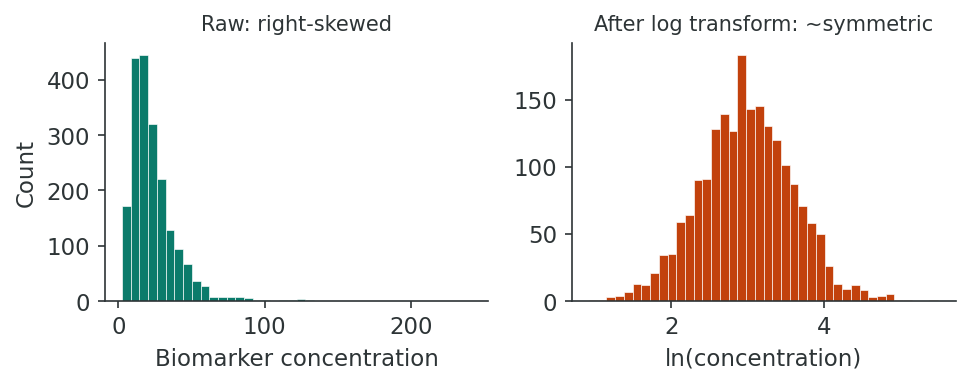
| Transformation | Formula | When to Use |
|---|---|---|
| Log (natural) | ln(x) or ln(x + 1) | Right-skewed data, multiplicative relationships (e.g., biomarker concentrations, income) |
| Square root | √x | Count data, moderately right-skewed distributions |
| Inverse (reciprocal) | 1/x | Strongly right-skewed data; commonly used for rates and times |
Remember
When you transform a variable, all subsequent interpretations must account for the transformation. For example, a regression coefficient from a log-transformed outcome represents a multiplicative (rather than additive) change. Always back-transform results for reporting.
Recoding and Derived Variables
Recoding involves creating new variables from existing ones. Common examples include collapsing categories (e.g., combining “current smoker” and “former smoker” into “ever smoker”), categorizing continuous variables into clinically meaningful groups (e.g., BMI categories), and computing derived variables such as person-years of follow-up or age at onset.
String Cleaning and Standardization
Free-text fields often contain inconsistencies: “Vancouver,” “vancouver,” “VANCOUVER,” and “Vancoouver” may all refer to the same city. Standardization strategies include converting to consistent case, trimming whitespace, applying regular expressions for pattern matching, and using lookup tables or fuzzy matching algorithms.
Documenting the Cleaning Process
Every data cleaning decision should be recorded in an audit trail. This includes what was changed, why, by whom, and when. Reproducibility requires that another analyst could replicate the cleaning process from the original raw data using your documentation, an expectation echoed in the Statistical Methods in Psychology Journals guidelines (Wilkinson & the Task Force on Statistical Inference, 1999).
This block uses the course dataset phaa_survey.csv, a simulated public-health survey of ~800 adults that we will reuse from this lesson onward. The full annotated script lives in r-activities/HSCI_410_Lesson_2_Data_Cleaning_and_Descriptive_Analyses.R.
# 1. Read the raw file. Treat blank cells as missing (na.strings).
phaa <- read.csv(file = "phaa_survey.csv",
stringsAsFactors = FALSE,
na.strings = c("", "NA"))
# 2. Convert variables that should be numeric (some came in as character
# because the raw data contained impossible values like a negative age).
phaa$age <- as.numeric(phaa$age)
phaa$bmi <- as.numeric(phaa$bmi)
# 3. Range checks: replace impossible values with NA
phaa$age[phaa$age < 18 | phaa$age > 100] <- NA
phaa$systolic_bp[phaa$systolic_bp < 80 | phaa$systolic_bp > 220] <- NA
phaa$bmi[phaa$bmi < 13 | phaa$bmi > 60] <- NA
# 4. Order education and income so that comparisons (<= ...) are meaningful
phaa$education <- factor(phaa$education,
levels = c("Less than high school", "High school", "Some college",
"Bachelor's", "Graduate degree"),
ordered = TRUE)Why never overwrite the raw file? Range-check rules will change as you learn more about the data. Keeping phaa_survey.csv untouched lets you replay the cleaning from a known starting state.
R Reflect on what you just ran
Use the questions below to interpret the output you produced. Look at your console / plot before answering.
1. Look at summary(phaa$age) before and after the line phaa$age <- as.numeric(phaa$age). How many NAs appear, and what does that count tell you about the raw data quality?
as.numeric(), age is character, so summary() reports only its length, class, and mode, not quartiles or an NA count. After conversion, summary() reports several NAs, typically 5–30 in the simulated dataset, representing entries that couldn't be parsed as numeric (text such as "unknown", "30s", or blank). The NA count is a direct measure of data-quality flaws in the raw entry: each NA is a hidden free-text response that the original data collection accepted but cannot be analysed quantitatively.2. After the range-check on systolic_bp, how many rows were set to NA? Why is replacing impossible values with NA preferable to deleting those rows entirely?
3. After making education an ordered factor, what does levels(phaa$education) show? Why does the ordering matter for any analysis that asks "as education goes up, does X change?"
levels(phaa$education) shows them in the specified order, e.g., "<HS" < "HS" < "Some college" < "Bachelor's" < "Graduate". Ordering matters because an ordered factor lets R interpret "higher education" as a meaningful direction in regression and tests, so linear contrasts become interpretable, and trend tests (Cochran-Armitage, ordinal regression) work as intended. Without the ordering R defaults to alphabetical, which makes "Bachelor's" < "Graduate" < "HS" < "Some college" < "<HS", which is nonsensical for inferential purposes.A cohort study of cardiovascular disease collected blood pressure measurements on 2,400 participants. During cleaning, 15 systolic values exceeded 300 mmHg. The analyst traced 12 of these to a decimal-point shift (e.g., 1,200 instead of 120.0) and corrected them using the original paper forms. Three could not be verified and were set to missing with a note: “Original form illegible; value implausible.” All decisions were logged in a cleaning script with date stamps.
Reflection
Think about a dataset you have worked with (or imagine a large epidemiologic study). What data cleaning challenges would you expect, and how would you prioritize your cleaning steps? What would your audit trail include?
1. What is the primary disadvantage of mean imputation for handling missing data?
2. Which outlier detection method is most robust for skewed distributions?
3. A log transformation is most appropriate for which type of distribution?
● Complete the reflection and knowledge check to continue.
Descriptive Analyses
Introduction and Overview
Earlier sections produced a clean, well-documented dataset. This section turns that dataset into the descriptive summaries that any analysis report opens with: means and medians, spreads and shapes, and frequency distributions, “Table 1” characteristics by exposure group, and the visualisations that go with them. Doing this carefully is what lets readers understand what your data look like before they trust your inferential models.
Learning Objectives
- Choose the appropriate measure of central tendency, spread, and shape for each variable type and distribution.
- Build frequency distributions and cross-tabulations to summarise categorical data.
- Select visualisations that match the variable type and the question you are asking.
- Construct a publication-ready “Table 1” of participant characteristics, including stratified comparisons.
- Assess normality and decide when a transformation or non-parametric approach is warranted.
Measures of Central Tendency
Measures of central tendency summarize the “typical” value in a distribution. The choice depends on the variable type and distributional shape.
The arithmetic mean (x̄) is the sum of all values divided by the number of observations. It uses all data points and is the basis of many parametric statistical methods.
When to use: Symmetric or approximately normal distributions. Avoid for heavily skewed data or when outliers are present, as the mean is pulled toward extreme values.
The median is the middle value when observations are ordered from smallest to largest. For an even number of observations, it is the average of the two middle values.
When to use: Skewed distributions, ordinal data, or when outliers are present. The median is robust to extreme values; unlike the mean, adding or removing an outlier has minimal effect on the median.
The mode is the most frequently occurring value. A distribution may be unimodal, bimodal, or multimodal.
When to use: Categorical (nominal) data, where neither the mean nor the median is meaningful. It is also useful for identifying common response values in continuous data (e.g., digit preference).
Measures of Spread
Spread (or dispersion) describes how much variability exists in the data around the central value.
| Measure | Formula / Definition | Properties |
|---|---|---|
| Range | Maximum − Minimum | Sensitive to outliers; uses only 2 data points |
| Variance (s²) | Σ(xi − x̄)² / (n − 1) | Average squared deviation; units are squared |
| Standard Deviation (s) | √s² | Same units as original variable; most commonly reported |
| IQR | Q3 − Q1 | Robust to outliers; covers middle 50% of data |
Two of these formulas often trip up beginners. The variance divides by n − 1 rather than n because the deviations are measured from the sample mean, not the unknown true mean; dividing by n would systematically understate the spread, and using the slightly smaller n − 1 corrects for it. The standard deviation is then simply its square root, which brings the value back from squared units (squared mmHg, for instance) to the original scale so it can sit beside the mean.
Reporting Convention
For normally distributed variables, report mean ± SD. For skewed distributions, report median (IQR) or median (Q1, Q3). This convention is standard in epidemiologic publications and should be followed in “Table 1” (Wilkinson & the Task Force on Statistical Inference, 1999).
Measures of Shape
Beyond central tendency and spread, the shape of a distribution provides critical information for choosing analytical methods.
Skewness measures the asymmetry of a distribution. A skewness of 0 indicates perfect symmetry.
- Positive (right) skew: Long right tail; mean > median. Common in variables like income, hospital length of stay, and biomarker concentrations.
- Negative (left) skew: Long left tail; mean < median. Less common but seen in variables like age at death in developed countries.
As a rule of thumb, |skewness| > 1 indicates substantial skew, though this depends on sample size.
Kurtosis describes the “tailedness” of a distribution relative to a normal distribution (which has a kurtosis of 3, or excess kurtosis of 0).
- Leptokurtic (excess kurtosis > 0): Heavier tails and a sharper peak; more extreme values than expected under normality.
- Platykurtic (excess kurtosis < 0): Lighter tails and a flatter peak; fewer extreme values than expected.
High kurtosis can indicate the presence of outliers or a mixture of subpopulations.
Frequency Distributions and Cross-Tabulations
For categorical variables, frequency distributions display the count and percentage of observations in each category. Cross-tabulations (contingency tables) display the joint distribution of two categorical variables and are the basis for computing measures of association such as odds ratios and risk ratios.
| Cases (n) | Controls (n) | Total | |
|---|---|---|---|
| Exposed | 45 | 30 | 75 |
| Unexposed | 15 | 60 | 75 |
| Total | 60 | 90 | 150 |
From this 2×2 table, the odds ratio = (45 × 60) / (30 × 15) = 2,700 / 450 = 6.0, suggesting a strong association between exposure and disease.
Visualization Techniques
Appropriate visualization depends on the variable type and the question being asked. Exploratory data analysis emphasises looking at data first so structure, gaps, and anomalies are visible before any model is fit.
Histograms display the distribution of a continuous variable by dividing values into bins and counting observations per bin. They reveal distributional shape, modality, gaps, and potential outliers. The choice of bin width affects interpretation: too few bins obscure patterns, too many create noise.
Boxplots display the median, IQR, whiskers (typically 1.5×IQR), and individual outliers. They are ideal for comparing distributions across groups (e.g., blood pressure by treatment arm) and for quickly identifying asymmetry and outliers.
Bar charts display frequencies or proportions for categorical variables. Use them for comparing counts across groups. Avoid using bar charts for continuous data (use histograms instead) and avoid 3D bar charts, which distort proportions.
Scatter plots display the relationship between two continuous variables and can reveal linear or nonlinear associations, clusters, and outliers. Line graphs are appropriate for displaying trends over time (e.g., incidence rates by year). Both are essential in epidemiologic exploratory analysis.
Continuing from the cleaning block above, calculate descriptives and produce the four standard plots. Base R is enough; psych::describe() is convenient for many variables at once.
# Categorical descriptives ---------------------------------------------------
table(phaa$gender) # frequencies
prop.table(table(phaa$gender)) # proportions
round(prop.table(table(phaa$gender)) * 100, 1) # %
# Cross-tab: gender by smoker, row percentages
round(prop.table(table(phaa$gender, phaa$smoker), margin = 1) * 100, 1)
# Numeric descriptives --------------------------------------------------------
summary(phaa$age)
sd(phaa$age, na.rm = TRUE)
IQR(phaa$age, na.rm = TRUE)
# psych::describe() summarises many variables at once
library(psych)
describe(phaa[, c("age", "bmi", "systolic_bp", "phys_act_min")])
# Plots: histogram, boxplot stratified by exposure, bar chart -----------------
hist(phaa$systolic_bp, main = "Systolic BP", xlab = "mmHg")
boxplot(systolic_bp ~ smoker, data = phaa,
main = "Systolic BP by smoking status", ylab = "mmHg")
barplot(table(phaa$gender), main = "Gender distribution")Tip: always plot before you fit a regression. A boxplot of systolic_bp by smoker tells you in a second whether the comparison you are about to do in a later lesson will be driven by a few extreme values or by a real shift in the centre of the distribution.
R Reflect on what you just ran
Use the questions below to interpret the output you produced. Look at your console / plot before answering.
1. From round(prop.table(table(phaa$gender, phaa$smoker), margin = 1) * 100, 1), which gender category has the highest percentage of current smokers? What is the magnitude of the gender gap in smoking?
2. From describe(phaa[, c("age", "bmi", "systolic_bp", "phys_act_min")]), which variable has the largest skew? Which is most clearly approximately normal? How would you justify reporting median (IQR) vs mean (SD) for each in a Table 1?
describe() from psych returns skew values for each variable. Physical-activity minutes typically have the largest skew (right-skewed: most people moderate, a few very high), while age and BMI are roughly normal. For Table 1: report median (IQR) for skewed variables (phys_act_min) because the median is less pulled by extremes; report mean (SD) for approximately normal variables (age, BMI). Systolic BP is moderately skewed and either summary works, though many epidemiology journals default to mean (SD) for clinical readability.3. Look at the boxplot(systolic_bp ~ smoker). Does the median for smokers appear higher, lower, or similar to non-smokers? Are there any visible outliers, and would you expect them to bias a t-test of the difference in means?
Descriptive Statistics for Epidemiologic Data: “Table 1”
In epidemiologic publications, “Table 1” typically presents the baseline characteristics of the study population, often stratified by exposure or outcome status. How time-to-event outcomes and group comparisons are displayed alongside Table 1 has been the subject of methodological scrutiny. Pocock, Clayton, & Altman (2002) catalogue common pitfalls in survival plots and baseline reporting. A well-constructed Table 1 includes:
- Demographics (age, sex, ethnicity) with appropriate summary statistics
- Key clinical or exposure variables
- Missing data counts for each variable
- Comparison statistics (p-values or standardized differences) between groups
| Characteristic | Exposed (n=200) | Unexposed (n=300) | p-value |
|---|---|---|---|
| Age, mean ± SD | 52.3 ± 11.4 | 49.8 ± 12.1 | 0.02 |
| Female, n (%) | 110 (55.0%) | 162 (54.0%) | 0.82 |
| BMI, median (IQR) | 27.1 (24.0–31.5) | 25.8 (23.2–29.4) | 0.004 |
| Current smoker, n (%) | 48 (24.0%) | 51 (17.0%) | 0.05 |
| Diabetes, n (%) | 34 (17.0%) | 30 (10.0%) | 0.02 |
Note how continuous variables with normal distributions use mean ± SD, while skewed variables (BMI) use median (IQR). Categorical variables are presented as n (%).
Stratified Descriptive Analyses
Stratifying descriptive statistics by key exposure or covariate groups allows you to assess the distribution of potential confounders across exposure categories. This is a critical step before proceeding to multivariable modelling, as it helps identify imbalances that may require adjustment.
Building Scales: Internal Consistency and Factor Analysis
Many public-health surveys ask several items that together measure a latent construct (e.g., depression, anxiety, social support). Two questions need to be answered before you can use these items as a single scale variable in a regression: (1) internal consistency (do the items hang together?), assessed with Cronbach’s α; and (2) dimensionality (how many underlying factors do the items measure?), assessed with exploratory factor analysis (EFA). Once both checks pass, the items can be summed (or averaged) into a derived scale variable that you carry forward into later lessons.
The course dataset contains seven depression items (dep1 … dep7) and five anxiety items (anx1 … anx5). Below we (1) confirm internal consistency, (2) decide on the number of factors, and (3) build the derived scale scores we use for the rest of the course.
# 1. Internal consistency for each candidate scale ----------------------------
library(psych)
dep_items <- phaa[, c("dep1","dep2","dep3","dep4","dep5","dep6","dep7")]
anx_items <- phaa[, c("anx1","anx2","anx3","anx4","anx5")]
alpha(dep_items) # raw_alpha >= 0.70 is acceptable, >= 0.80 is good
alpha(anx_items)
# 2. How many underlying factors? ------------------------------------------
fa.parallel(dep_items) # scree plot suggests one factor
# 3. Inspect a one-factor solution for the depression items ----------------
factanal(x = dep_items, factors = 1, rotation = "varimax")
# Loadings >= ~0.40 contribute meaningfully to the factor.
# 4. Two-factor solution combining dep + anx items -------------------------
combined <- na.omit(cbind(dep_items, anx_items))
factanal(x = combined, factors = 2, rotation = "varimax")
# dep1-7 should load on one factor; anx1-5 on the other.
# 5. Build derived scale variables for use in later lessons ------------------
phaa$dep_score <- rowSums(dep_items, na.rm = TRUE)
phaa$anx_score <- rowSums(anx_items, na.rm = TRUE)
summary(phaa$dep_score)
# 6. Save the cleaned, scale-augmented file --------------------------------
write.csv(phaa, "phaa_survey_clean.csv", row.names = FALSE)How to read this. A α near 0.90 says the seven depression items are measuring essentially the same construct. The single factor explains a large share of the variance and every item loads > 0.50 on it, so summing the items into a dep_score is justified. We will use this score as a continuous predictor in a later lesson and as a covariate in the logistic model for hypertension in a later lesson.
R Reflect on what you just ran
Use the questions below to interpret the output you produced. Look at your console / plot before answering.
1. What is the raw alpha for the depression items? For the anxiety items? Which scale (if either) clears the conventional 0.80 threshold for "good" internal consistency, and which item (look at the "Reliability if an item is dropped" table) contributes least to the depression scale?
2. From fa.parallel(dep_items), how many factors have eigenvalues above the parallel-analysis line? Does the one-factor solution from factanal() show all seven loadings >= 0.40?
fa.parallel() typically shows one factor above the parallel-analysis line for the depression items, supporting a unidimensional structure. The one-factor solution from factanal() usually has all seven loadings ≥ 0.40, confirming that all items track the same latent construct.3. In the two-factor combined solution, do the depression items load on a different factor than the anxiety items? Cite one specific loading from your output that supports your answer.
Normality Assessment
Assessing whether a variable follows a normal distribution informs the choice between parametric and non-parametric methods.
Q-Q (quantile-quantile) plots compare observed quantiles to theoretical normal quantiles. Points falling along the diagonal line suggest normality; systematic departures indicate non-normality. Histograms with a normal curve overlay also provide quick visual assessment.
The Shapiro-Wilk test is generally preferred for samples under 5,000. The Kolmogorov-Smirnov test (with Lilliefors correction) is an alternative. Both test the null hypothesis that data come from a normal distribution.
Caveat: With very large samples, these tests will reject normality even for trivial departures. Visual assessment should always accompany formal tests.
Implications for Analysis Choice
If a variable is approximately normal, parametric tests (t-tests, ANOVA, Pearson correlation) are appropriate. For non-normal distributions, consider non-parametric alternatives (Wilcoxon rank-sum, Kruskal-Wallis, Spearman correlation) or data transformations. The Central Limit Theorem provides some protection for large samples, but descriptive summaries should still reflect the actual distribution.
Reflection
Consider how you would construct a “Table 1” for an epidemiologic study examining the relationship between physical activity and cardiovascular disease. What variables would you include, how would you summarize each, and what stratification would you use?
1. For a heavily right-skewed variable, which summary statistics should be reported?
2. A distribution has excess kurtosis greater than 0. What does this indicate?
3. What is the primary purpose of stratifying descriptive statistics by exposure group in epidemiologic research?
4. A Shapiro-Wilk test yields p < 0.001 with a sample of 50,000. Which interpretation is most appropriate?
● Complete the reflection and knowledge check to continue.
Final Assessment
Bringing It All Together
This lesson followed a single dataset from raw to descriptive. An earlier section named the errors (collection, entry, storage, and analysis-stage problems), and unpacked the missing-data mechanisms (MCAR, MAR, MNAR) that determine which cleaning approaches are even valid. An earlier section turned that vocabulary into a workflow: systematic range, type, and consistency checks; outlier triage; principled missing-data handling; transformations and derived variables; and a documentation trail you could hand to a peer reviewer. An earlier section closed the loop with the descriptive layer that every paper opens with: central tendency, spread, shape, frequency tables, and visualisations, and a Table 1 that stratifies on the primary exposure or outcome.
The point is that descriptive analysis is not a warm-up. It is the layer where data problems surface, where assumptions get tested, and where readers calibrate how much trust to place in the inferential models that follow. From here we can move into the regression machinery of the rest of the course knowing that the dataset under it has been understood, not just processed.
Key Takeaways from this lesson
- Errors enter the data pipeline at every stage; cleaning is about locating them, not arbitrarily fixing values.
- The missing-data mechanism (MCAR, MAR, MNAR) determines which handling strategies remain valid; complete-case analysis is rarely defensible.
- Outliers should be investigated, not deleted by reflex; document keep/exclude/transform decisions.
- Choose central tendency, spread, and shape statistics based on variable type and distributional shape.
- A well-built Table 1 stratified by exposure or outcome is often the most informative single output of an analysis.
- Cleaning and descriptive work must leave a documented trail; reproducibility is not optional.
Reflection
Reflecting on the entire lesson, describe a systematic workflow you would follow when receiving a new epidemiologic dataset, from initial data quality assessment through to producing a complete descriptive summary. What tools, checks, and documentation would you use at each step?
data/raw/ with a SHA-256 checksum. (2) Inventory: structural read (rows, columns, types), summary of every variable. (3) Variable-by-variable cleaning: range checks, plausibility, missing-data codes. (4) Derivation: build analytic variables (age groups, BP categories, composite scales). (5) Descriptive summary: univariate and bivariate, by exposure or outcome. (6) Diagnostic report: HTML/PDF auto-generated showing distribution plots, missingness, and outlier counts for each variable. (7) Codebook: machine-readable (JSON/YAML) accompanying the cleaned dataset, with derivation logic for each variable. Tools: R (tidyverse + janitor + summarytools), Python (pandas + great_expectations) or Stata (codebook + ds), with Git for code, DVC for data, and Quarto/Rmd for the diagnostic report. Documentation at every step: the decision log explains every NA, every recode, every dropped row.Final Knowledge Assessment
You must answer all 15 questions correctly (100%) and complete the final reflection to finish this lesson.
1. Which stage of the data pipeline is most susceptible to transcription errors?
2. In a dataset where missingness of income depends on the actual income value itself (high earners are less likely to report), the missing data mechanism is:
3. Which method for handling missing data correctly accounts for imputation uncertainty?
4. Using the IQR method, a value is classified as an outlier if it falls:
5. What is the primary limitation of listwise deletion?
6. For a normally distributed continuous variable, the conventional summary statistics to report are:
7. A variable measuring “number of emergency department visits in the past year” is best classified as:
8. Which visualization is most appropriate for comparing the distribution of a continuous variable across three treatment groups?
9. In a cross-tabulation of exposure and disease, the odds ratio is computed as:
10. Positive skewness indicates that:
11. What is the purpose of a Q-Q plot?
12. When applying a natural log transformation to a variable that contains zero values, the appropriate approach is to:
13. In a “Table 1” for an epidemiologic study, categorical variables are typically summarized as:
14. Which statement about the z-score method for outlier detection is correct?
15. An audit trail for data cleaning should include all of the following EXCEPT:
✦ Before submitting: pass every section knowledge check (100%) and complete every reflection.