Risk in E+
–
Fundamental Epidemiological Concepts and Approaches
This course was developed by Dr. Kiffer G. Card, Faculty of Health Sciences, Simon Fraser University based on Dohoo, I. R., Martin, S. W., & Stryhn, H. (2012). Methods in Epidemiologic Research. VER Inc.
📚 Reference page, available throughout the lesson
This glossary collects the key concepts, people, and ideas you will meet in this lesson. Use it as a reference while you work through the material, or as a review before assessments. Type in the search box to filter entries.
⏱ Estimated reading time: 15 minutes
An earlier lesson gave us measures of disease frequency: prevalence, incidence, risk, and rate. An earlier lesson took the same probabilistic vocabulary and applied it at the level of a single test. This lesson brings these strands together: it combines the disease-frequency vocabulary with the 2×2 contingency logic to produce measures of association, the quantitative comparison between exposed and unexposed groups that is the central output of analytic epidemiology. The four content sections build up from the three ratio measures (this section: risk ratio, rate ratio, odds ratio), through difference measures and exposed-group attributable fractions (a later section), to population-level attributable measures and how each measure relates to study design (a later section), and finally to the hypothesis-testing and confidence-interval machinery that turns each of these point estimates into a defensible inference (a later section).
Measures of association assess the magnitude of the relationship between an exposure (a potential cause) and a disease. Unlike measures of statistical significance, which are heavily dependent on sample size, measures of association indicate the strength of the effect, that is, how much more (or less) likely disease is in exposed compared to non-exposed groups (Tripepi et al., 2007).
A measure of association tells you how strongly an exposure is linked to disease. A P-value tells you how likely the observed data would be under the null hypothesis of no association. A strong association can be non-significant (small sample), and a weak association can be highly significant (large sample). Always report both.
Depending on study design, disease frequency can be expressed as incidence risk, incidence rate, prevalence, or odds. For risk data, the standard 2×2 table is:
| Exposed | Non-exposed | Total | |
|---|---|---|---|
| Diseased | a1 | a0 | m1 |
| Non-diseased | b1 | b0 | m0 |
| Total | n1 | n0 | n |
For rate data, the denominator is person-time at risk rather than the number of individuals:
| Exposed | Non-exposed | Total | |
|---|---|---|---|
| Number of cases | a1 | a0 | m1 |
| Person-time at risk | t1 | t0 | t |
A quick word on odds, since the third measure below is built from them. The risk of an outcome is the number of cases divided by everyone at risk, meaning cases plus non-cases. The odds of the same outcome is the number of cases divided by the non-cases alone. If 20 of 100 people get sick, the risk is 20/100 = 0.20, but the odds are 20/80 = 0.25. Risk and odds stay close while an outcome is uncommon and pull apart as it becomes common, which is the same fact that lets the odds ratio stand in for the risk ratio only when disease is rare.
Click each card to learn more:
| Water Cistern | No Cistern | Total | |
|---|---|---|---|
| Diarrhea Present | 194 | 303 | 497 |
| Diarrhea Absent | 1,588 | 1,314 | 2,902 |
| Total | 1,782 | 1,617 | 3,399 |
Both measures indicate that having a water cistern is protective against diarrhea (values < 1). The RR of 0.58 means the risk is 42% lower among those with cisterns.
| Female | Male | Total | |
|---|---|---|---|
| Cases of migraine | 131 | 44 | 175 |
| Person-months | 250 | 236 | 486 |
IR = (131/250) / (44/236) = 0.524 / 0.186 = 2.81
The rate of migraine is 2.81 times higher in females than males aged 30–40.
In general, IR values are further from the null (1) than RR values, and OR values are even further away (Cornfield, 1951; Knol et al., 2008). This can be visualised on a number line:
Figure 6.1. General relationships among RR, IR, and OR. OR is always furthest from the null value of 1.
When the disease is rare (prevalence or incidence risk < 5%), OR approximates RR, the classic Cornfield (1951) approximation used by Doll and Hill (1950) in their landmark case-control study of smoking and lung cancer. This is because when a1 is small relative to n1, the denominator of the odds (b1) is approximately equal to n1, and similarly for the non-exposed group. In the cistern example, the overall risk was 14.6%, so OR (0.53) was more extreme than RR (0.58); when outcomes are not rare, treating OR as RR can substantially overstate the effect (Knol et al., 2008).
RR and IR will be close to each other if the exposure has a negligible impact on the total time at risk in the study population. This occurs when the disease is rare or when IR is close to the null value (IR ≈ 1).
OR is a good estimator of IR under certain conditions in case-control studies. If controls are selected using cumulative or risk-based sampling (all non-cases after cases have occurred), then OR estimates IR only if the disease is rare. If controls are selected using density sampling (a control selected from non-cases each time a case occurs), then OR is a direct estimate of IR regardless of disease rarity.
Edit any cell of the 2×2 (or use the slider for outcome prevalence). Watch how OR ≈ RR when the outcome is rare, but the two diverge dramatically as the outcome becomes common: OR always overstates RR when RR > 1, and understates it when RR < 1.
| Y+ | Y− | Total | |
|---|---|---|---|
| E+ | 40 | 60 | 100 |
| E− | 20 | 80 | 100 |
1. The odds ratio (OR) is the only ratio measure of association applicable to case-control studies because:
2. A risk ratio of 0.58 for diarrhea in a cistern study indicates:
3. Under what condition does OR best approximate RR?
✦ Pass the knowledge check with 100% to continue
⏱ Estimated reading time: 15 minutes
An earlier section covered the three ratio measures (RR, IR, OR), that is, how many times more likely disease is in the exposed group compared to the unexposed. This section turns to the parallel set of difference measures, which answer a different question: not how many times more, but how many extra cases occur because of the exposure. Difference measures lead naturally to attributable fractions in the exposed, which quantify how much disease in the exposed group can be attributed to the exposure itself.
The ratio measures from an earlier section (RR, IR, OR) tell us the relative strength of association, but they do not indicate the absolute number of cases attributable to the exposure. Difference (absolute effect) measures address this gap by computing how many additional cases occur because of the exposure; the choice between ratio and difference measures is itself a substantive scientific decision rather than a statistical convenience (Greenland & Pearce, 2015; Tripepi et al., 2007).
It helps to name the two scales this contrast lives on. Ratio measures work on a multiplicative scale: a risk ratio of 2 says the exposed risk is the baseline risk multiplied by two. Difference measures work on an additive scale: a risk difference of 0.04 says the exposed risk is the baseline plus four percentage points. The same association can look striking on one scale and slight on the other, so the choice of scale is a real part of the scientific question rather than a matter of presentation.
Even when an exposure is very strongly associated with disease (high RR), if the exposure is rare in a population, it may contribute very few cases. Conversely, a relatively weak risk factor (modest RR) that is common can be responsible for many cases. Difference measures capture this “public health impact.”
The risk difference (RD), also called attributable risk (Walter, 1976), is simply the risk in the exposed group minus the risk in the non-exposed group:
Similarly, the incidence rate difference (ID) is the difference between two incidence rates:
RD indicates the increase (or decrease) in the probability of disease in the exposed group, beyond the baseline risk. It tells you: “For every X exposed individuals, how many additional cases occur because of the exposure?”
From a cohort of 5,000 women followed through pregnancy:
| Smoker | Non-smoker | Total | |
|---|---|---|---|
| Low birth weight | 40 | 331 | 371 |
| Normal birth weight | 311 | 4,318 | 4,629 |
| Total | 351 | 4,649 | 5,000 |
For every 100 women who smoked, approximately 4.3 had a low-birth-weight baby due to the fact that they smoked (assuming causal relationship).
The AFe (also called the attributable fraction among the exposed) expresses the proportion of disease in exposed individuals that is due to the exposure, assuming the relationship is causal (Walter, 1976). It can be viewed as the proportion of disease in the exposed group that would be avoided if the exposure were removed.
AFe ranges from 0 (where risk is equal, RR = 1) to 1 (where all disease in the exposed group is due to the exposure, RR = ∞). In case-control studies, AFe can be approximated by substituting OR for RR.
From the smoking example above:
Among women who smoked, 37.5% of the low-birth-weight cases were attributable to smoking. Alternatively: 0.043 / 0.114 = 0.377 ≈ 37.7% (slight rounding difference).
Vaccine efficacy is a special form of AFe, where “not vaccinated” is the exposure (factor positive) and “vaccinated” is the comparison group. If 20% of unvaccinated individuals develop disease versus 5% of vaccinated individuals:
The vaccine has prevented 75% of the cases of disease that would have occurred in the vaccinated group if the vaccine had not been used.
The etiologic fraction is the proportion of cases in the exposed group for which exposure was a component of the sufficient cause (Rothman, 1976). While AFe measures the excess fraction, the etiologic fraction can be higher because exposure may contribute to cases even when the baseline risk would have produced them eventually. In general, AFe provides a lower bound for the etiologic fraction (Greenland & Robins, 1988).
In a cohort study, a new environmental pollutant is found to have an RR of 3.0 for respiratory disease. The risk of respiratory disease in the non-exposed population is 2%. Calculate the RD and AFe. If 1,000 people are exposed, how many additional cases would you expect due to the exposure? Discuss why RD and AFe give different but complementary perspectives.
Minimum 20 characters required.
1. If the risk of disease is 12% in the exposed group and 4% in the non-exposed group, the risk difference (RD) is:
2. A vaccine efficacy of 75% means:
3. AFe = (RR − 1)/RR. If RR = 2.5, what is AFe?
✦ Pass the knowledge check with 100% and complete the reflection to continue
⏱ Estimated reading time: 12 minutes
Earlier sections worked at the level of the exposed group. This section zooms out: even if an exposure powerfully causes disease in the exposed, its public-health importance also depends on how common it is in the population. The population attributable fraction (AFp) captures this combination, and the section closes by mapping each measure of association onto the study design that produces it, tying back to earlier lessons.
While RD and AFe describe the effect of exposure among exposed individuals, public health decisions often require understanding the impact of an exposure on the entire population. Two key population-level measures address this:
The PAR is the increase in overall population risk attributable to the exposure. It reflects both the strength of the association and the frequency of the exposure in the population, an idea originally developed by Levin (1953) for lung cancer and reviewed by Northridge (1995) as a link between causal inference and public-health action.
The AFp indicates the proportion of disease in the entire population that is attributable to the exposure, and which would be avoided if the exposure were removed (assuming causation and no confounding).
A strong risk factor (high RR) that is rare in the population will have a small AFp. A weaker risk factor (modest RR) that is common may have a large AFp. For example, intravenous drug use has a very high RR for HIV, but if it is rare in the population, eliminating it would prevent few total cases. A modestly elevated risk factor like poor diet, affecting millions, may account for more total cases.
From the cohort of 5,000 women (351 smokers, 4,649 non-smokers):
Only 4.1% of all low-birth-weight babies in the population were attributable to smoking. The low AFp is because very few women (351/5000 = 7%) smoked during the 2nd trimester, despite the relatively strong association (RR = 1.60).
If confounding is present, adjusted estimates of RR should be used. The AFp can then be estimated using:
where pd is the proportion of cases exposed to the risk factor, and aRR is the adjusted risk ratio. For multiple exposure categories, a summation formula is used.
Not all measures can be computed from all study designs. The following table summarises which measures are available:
| Measure | Cross-sectional | Cohort | Case-control |
|---|---|---|---|
| RR | ✓ | ✓ | |
| IR | ✓ | ||
| OR | ✓ | ✓ | ✓ |
| RD | ✓ | ✓ | |
| AFe | ✓ | ✓ | ✓b |
| PAR | ✓ | ✓a | |
| AFp | ✓ | ✓a | ✓c |
a Requires independent estimate of p(D+) or p(E+). b Estimated using OR. c Requires OR and independent estimate of p(E+|D+).
Consider two risk factors for a disease: Factor A has RR = 5.0 and affects 2% of the population. Factor B has RR = 1.5 and affects 40% of the population. Calculate AFp for each factor using the formula AFp = p(E+)(RR − 1) / [p(E+)(RR − 1) + 1]. Which factor would you prioritise in a public health intervention, and why?
Minimum 20 characters required.
1. A risk factor has RR = 4.0 but affects only 1% of the population. The AFp is:
2. Which measure cannot be computed directly from a case-control study?
3. PAR differs from RD in that:
✦ Pass the knowledge check with 100% and complete the reflection to continue
⏱ Estimated reading time: 15 minutes
Earlier sections produced point estimates of association: single numbers like RR = 2.5 or AFp = 30%. Those numbers are useless without a quantification of how uncertain they are. This section closes the lesson by introducing the standard error, hypothesis tests, and confidence intervals, the same statistical-inference machinery you previewed in an earlier course, now applied directly to the measures you just learned to compute.
The standard error (SE) provides a measure of the precision of a point estimate, that is, how much uncertainty exists in the estimate. For difference measures (RD, ID), the variance can be computed directly:
For ratio measures (RR, IR, OR), the variance is computed on the log scale using Taylor series approximations:
Significance testing is based on specifying a null hypothesis about the population parameter. The null hypothesis typically states there is no association:
An alternative hypothesis can be 1-tailed or 2-tailed. In general, 2-tailed hypotheses are preferred because 1-tailed hypotheses are harder to justify.
P-values are often dichotomised into “significant” or “non-significant” at α = 0.05, but this entails a huge loss of information (Wasserstein & Lazar, 2016; Greenland et al., 2016). A P-value of 0.049 and 0.051 lead to different conclusions despite being virtually identical. Always report the actual P-value and a confidence interval, which conveys both significance and precision.
Click each card to explore:
A confidence interval (CI) reflects the level of uncertainty in a point estimate. A 95% CI means that if the study were repeated many times under identical conditions, 95% of the computed CIs would contain the true parameter value. This is a property of the procedure, not a probability statement about the parameter (Greenland et al., 2016).
For difference measures, the CI is computed directly:
For ratio measures, the CI is computed on the log scale and then exponentiated:
The CI is symmetrical about lnθ but not about θ itself, which is why confidence intervals for ratio measures appear asymmetric.
However, this “surrogate significance test” is an under-use of the CI. The CI also shows the range of plausible effect sizes, which is far more informative than a binary significant/non-significant classification.
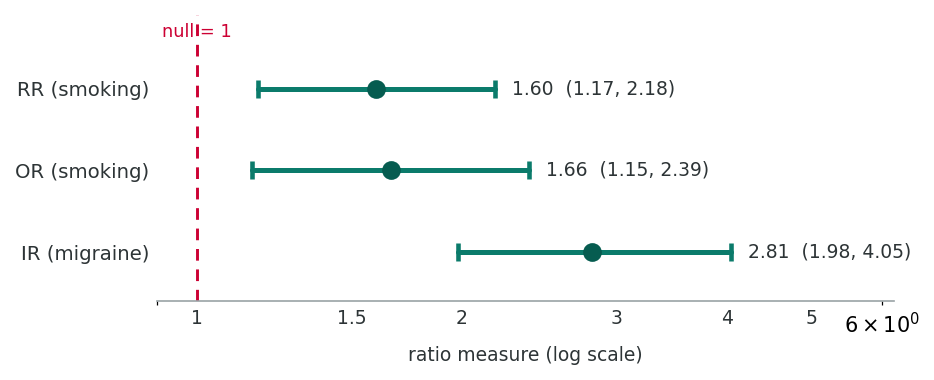
| Measure | Point Estimate | 95% CI |
|---|---|---|
| RD (smoking) | 0.043 | (0.009, 0.077) |
| RR (smoking) | 1.601 | (1.174, 2.182) |
| OR (smoking) | 1.678 | (1.154, 2.387) |
| ID (migraine) | 0.338 | (0.232, 0.443) |
| IR (migraine) | 2.811 | (1.983, 4.050) |
None of the CIs for ratio measures include 1, and none for difference measures include 0, confirming statistical significance for all associations.
The Pearson χ², Fisher’s exact, Wald, and likelihood ratio tests above are the workhorses for 2×2 tables and the regression-based measures of association you will meet in a later course. But epidemiological analyses often require comparing means, proportions, or whole distributions across groups, sometimes paired, sometimes not, sometimes badly skewed. The right test depends on three structural questions about your data:
The table below summarises the tests most commonly reported alongside measures of association. The R code that follows runs each on simple built-in datasets so you can copy, paste, and read the output without external data files.
| Test | When to use | How calculated | How to interpret |
|---|---|---|---|
| One-sample t-test | Compare a single sample mean to a known/hypothesised value μ0; continuous, approximately normal (or n large). | t = (x̄ − μ0) / (s/√n); df = n−1. | If p < α (or 95% CI for the mean excludes μ0), the population mean differs from μ0. |
| Two-sample (independent) t-test | Compare means of 2 independent groups; continuous, approximately normal. Welch’s version (R’s default) does not assume equal variances. | t = (x̄1 − x̄2) / SEdiff; df = n1+n2−2 (Student) or Welch–Satterthwaite df (Welch). | p < α → the two group means differ. Always report the mean difference and its 95% CI. |
| Paired t-test | Two related observations on the same unit (before/after, twin pairs, matched cases-controls); continuous differences approximately normal. | Compute within-pair differences di; t = d̄ / (sd/√n); df = n−1. | p < α → mean within-pair change ≠ 0. Reduces between-subject variability, and is usually more powerful than treating data as unpaired. |
| One-way ANOVA | Compare means across 3+ independent groups; continuous, approximately normal, roughly equal variances. | F = MSbetween / MSwithin; df1 = k−1, df2 = N−k. | Significant F → at least one group mean differs. Follow with post-hoc pairwise comparisons (Tukey HSD, Bonferroni) to see which. |
| Pearson χ² | Test independence of two categorical variables (any r×c table). Assumption: all expected counts > 1 and ≥ 80% > 5. | χ² = Σ(O−E)²/E; df = (r−1)(c−1). Expected = (row total × column total) / N. | p < α → row and column variables are associated. The test signals whether there is association; report a measure of association (OR, RR) for strength. |
| Fisher’s exact test | 2×2 (or larger) tables with small expected counts where the χ² approximation is suspect. | Hypergeometric: enumerates every table with the same margins, sums probabilities of tables as extreme or more extreme than observed. | Exact p-value, with no large-sample assumption. With modern computing, fine to use even when χ² would also be valid. |
| McNemar’s test | Paired/matched binary outcomes (before/after on the same person; matched case-control on exposure; agreement of two diagnostic tests). | Look only at discordant pairs b and c: χ² = (b−c)² / (b+c); df = 1. Concordant pairs ignored. | p < α → the discordant pairs are unbalanced, so a real change/effect exists. The matched OR is b/c. |
| Wilcoxon signed-rank | Non-parametric alternative to one-sample / paired t-test. Use when differences are skewed, ordinal, or have outliers. | Rank |di|, attach signs, sum positive (or negative) ranks; compare to its null distribution (or large-sample z). | p < α → the median difference is non-zero (under symmetry). Robust to outliers. |
| Mann–Whitney U (Wilcoxon rank-sum) | Non-parametric alternative to two-sample t-test. Two independent groups, continuous or ordinal. | Pool all observations, rank them, sum ranks in one group; U = R1 − n1(n1+1)/2. | p < α → the two distributions differ. If shapes are similar, this is a test of medians; otherwise it tests stochastic dominance. |
| Kruskal–Wallis | Non-parametric alternative to one-way ANOVA. 3+ independent groups; continuous or ordinal. | H from rank sums; approximately χ²k−1 under H0. | p < α → at least one group’s distribution differs. Follow with pairwise rank-sum tests (Dunn’s test or pairwise Wilcoxon with adjustment). |
| Pearson correlation (r) | Linear association between two continuous variables; assumes approximate bivariate normality, sensitive to outliers. | r = Σ(x−x̄)(y−ȳ) / √[Σ(x−x̄)² Σ(y−ȳ)²]; tested via t = r√[(n−2)/(1−r²)]. | Range −1 to +1: sign = direction, magnitude = strength of linear association. Always inspect a scatterplot first. |
| Spearman ρ | Monotonic (not necessarily linear) association between two ordinal or non-normally distributed continuous variables. | Pearson r applied to the ranks of x and y. | Same −1 to +1 interpretation, but for monotonic association. Robust to outliers and non-linearity. |
None of the tests above are themselves measures of effect size. A statistically significant chi-square confirms that some association exists, but the magnitude must come from the OR, RR, mean difference, or correlation coefficient. Likewise, a non-significant t-test in a small study is not evidence of no effect. Always pair every test with the corresponding effect estimate and its 95% CI.
R has all of these tests in base (no packages required). The blocks below use the built-in datasets ToothGrowth, sleep, and iris. Copy any block straight into your console.
R’s t.test() defaults to Welch’s two-sample t-test (no equal-variance assumption). Use var.equal = TRUE for the classic Student’s version. The paired = TRUE flag flips it to a paired t.
# --- ONE-SAMPLE t-test: is mean tooth length different from 18 mm? ---
t.test(ToothGrowth$len, mu = 18)
# --- TWO-SAMPLE (independent) t-test: OJ vs. VC supplements ---
t.test(len ~ supp, data = ToothGrowth) # Welch (default)
t.test(len ~ supp, data = ToothGrowth, var.equal = TRUE) # Student
# --- PAIRED t-test: sleep gain under two drugs, same 10 subjects ---
t.test(extra ~ group, data = sleep, paired = TRUE)
# --- ONE-WAY ANOVA: tooth length across 3 doses ---
ToothGrowth$dose <- factor(ToothGrowth$dose)
fit <- aov(len ~ dose, data = ToothGrowth)
summary(fit)
# Post-hoc pairwise comparisons (control familywise error)
TukeyHSD(fit)Reading the output
For t.test(): report t, df, p-value, the mean difference, and the 95% CI. For aov(): summary() gives the F-statistic and overall p; TukeyHSD() tells you which specific group pairs differ.
Diagnostic before you trust it. Check normality of residuals (plot(fit, which = 2)) and equal variances (Levene’s test, or plot(fit, which = 1)). If either fails badly, switch to the non-parametric box below.
Use the questions below to interpret the actual numbers you produced for the t-test and ANOVA block. Look at your console output before answering.
1. From the two-sample Welch t.test(len ~ supp, data = ToothGrowth), report the mean difference between OJ and VC and the 95% CI. Does the CI exclude 0?
2. From the paired t.test(extra ~ group, data = sleep, paired = TRUE), what mean difference in sleep gain did you observe and what was the p-value? Why does pairing the same 10 subjects give more power than treating the two columns as independent?
3. From summary(fit) and TukeyHSD(fit) on tooth length by dose, what does the overall ANOVA F-test say, and which specific dose-pairs in the Tukey output differ significantly?
For 2×2 tables build a matrix or table. R applies continuity correction by default for chisq.test() and mcnemar.test() on 2×2 tables; turn it off with correct = FALSE if you prefer the uncorrected statistic.
# --- 2x2 table: exposure x disease ---
exposure <- matrix(c(30, 70, 10, 90), nrow = 2, byrow = TRUE,
dimnames = list(exposure = c("E+", "E-"),
disease = c("D+", "D-")))
exposure
chisq.test(exposure) # Pearson chi-square (with Yates' correction)
chisq.test(exposure, correct = FALSE) # without correction
fisher.test(exposure) # exact test (preferred for small cells)
# --- McNemar's test: paired/matched binary data ---
# e.g. agreement between two diagnostic tests on the same 100 patients
paired <- matrix(c(40, 10,
25, 25), nrow = 2, byrow = TRUE,
dimnames = list(test1 = c("+", "-"),
test2 = c("+", "-")))
mcnemar.test(paired) # with continuity correction
mcnemar.test(paired, correct = FALSE) # withoutReading the output
chisq.test() returns χ², df, and p; check $expected for sparse cells. fisher.test() additionally returns the OR and its 95% CI, a free measure of association on top of the test. mcnemar.test() tests only the discordant pairs (10 vs 25 here); the matched OR is 10/25 = 0.4.
When to switch to Fisher. If any expected cell count drops below 5 (or any below 1), the χ² large-sample approximation is unreliable. chisq.test() will warn you; fisher.test() sidesteps the issue entirely.
Use the questions below to interpret your 2x2 table analyses. Look at the exposure matrix, the test output, and the McNemar output before answering.
1. From chisq.test(exposure) on the 2x2 table (30/70/10/90), report the chi-square statistic and p-value. By hand or by inspection, what is the odds ratio for this table, and what does the test conclude about independence?
2. From fisher.test(exposure), what OR and 95% CI did it return? How does this OR compare with the simple cross-product OR you can compute from the cells of the table?
3. McNemar's test only uses the off-diagonal (discordant) pairs - 10 and 25 in this example. What does the matched OR of 10/25 = 0.4 tell you about the two diagnostic tests, and why would a chi-square on the same table give a misleading answer?
The same wilcox.test() function covers both the Wilcoxon signed-rank (one-sample / paired) and Mann–Whitney U (two-sample) tests; the paired flag and the formula form decide which.
# --- WILCOXON SIGNED-RANK (one-sample / paired) ---
wilcox.test(ToothGrowth$len, mu = 18) # one-sample
wilcox.test(extra ~ group, data = sleep, paired = TRUE) # paired
# --- MANN-WHITNEY U / WILCOXON RANK-SUM (two-sample) ---
wilcox.test(len ~ supp, data = ToothGrowth)
# --- KRUSKAL-WALLIS (3+ groups, non-parametric ANOVA) ---
kruskal.test(len ~ dose, data = ToothGrowth)
# Post-hoc pairwise (Bonferroni-adjusted)
pairwise.wilcox.test(ToothGrowth$len, ToothGrowth$dose,
p.adjust.method = "bonferroni")
# --- CORRELATION: Pearson (linear) and Spearman (monotonic) ---
cor.test(iris$Sepal.Length, iris$Petal.Length, method = "pearson")
cor.test(iris$Sepal.Length, iris$Petal.Length, method = "spearman")Reading the output
Rank-based tests return a test statistic (W, U, or H) and a p-value. They do not give a CI for a mean difference; if you need one, use a Hodges–Lehmann estimator (conf.int = TRUE on wilcox.test()). cor.test() returns the correlation, its 95% CI (Pearson only by default), and the p-value.
Parametric or non-parametric? With n > ~30 per group the t-test and ANOVA are robust to mild non-normality (CLT), so reach for non-parametric tests mainly for skewed small samples, ordinal outcomes, or when outliers dominate. Spearman is also a sensible default whenever a scatterplot looks monotonic but not linear.
Use the questions below to interpret your non-parametric and correlation output. Look at your console results before answering.
1. Compare the p-values from t.test(len ~ supp, data = ToothGrowth) (earlier box) and wilcox.test(len ~ supp, data = ToothGrowth). Are they similar or different? What does that tell you about whether the t-test was robust here?
2. From cor.test(iris$Sepal.Length, iris$Petal.Length, method = "pearson"), report the correlation coefficient r and its 95% CI. How does the Spearman correlation compare, and what would a large discrepancy suggest about the relationship's shape?
3. From kruskal.test(len ~ dose, data = ToothGrowth), what was the H statistic and p-value? Which pairs in the pairwise.wilcox.test() with Bonferroni adjustment remained significant? Why does Bonferroni make this conclusion more conservative?
A study reports an OR of 1.45 with a 95% CI of (0.92, 2.28). A second study reports an OR of 1.15 with a 95% CI of (1.02, 1.30). Compare these two findings in terms of: (a) strength of association, (b) statistical significance, and (c) precision. Which finding might be more concerning from a public health perspective, and why?
Minimum 20 characters required.
1. A 95% confidence interval for an odds ratio is (1.2, 3.8). This means:
2. Why are confidence intervals for ratio measures (like OR) asymmetric around the point estimate?
3. Which test statistic is generally considered superior in regression settings?
✦ Pass the knowledge check with 100% and complete the reflection to continue
⏱ Estimated time: 20 minutes
This lesson translated the disease-frequency measures of an earlier lesson into measures of association between an exposure and an outcome. You worked through the three ratio measures (RR, IR, OR), the difference measures of effect in the exposed (RD, AFe), the population-level extensions (PAR, AFp), and the inferential machinery (standard errors, hypothesis tests, confidence intervals) that surrounds every estimate.
A later lesson returns to study-design topics first introduced in an earlier course and consolidates them; later lessons cover hybrid designs (nested case-control, case-cohort, case-crossover) and controlled trials. The measures you computed here will reappear in each of those lessons as the outputs that designs deliver and that systematic reviews eventually pool. For deeper treatment of these measures and their statistical foundations, see Greenland and Pearce (2015) and the historical landmark papers by Cornfield (1951) and Doll and Hill (1950).
A colleague presents findings from a case-control study showing OR = 2.3 (95% CI: 1.1, 4.8) for the association between a workplace chemical exposure and bladder cancer. She concludes the chemical “causes 2.3 times the risk of bladder cancer.” Evaluate this statement. What can and cannot be concluded from this study? Discuss the roles of strength of association, statistical significance, the rare disease assumption, and the distinction between OR and RR.
Minimum 20 characters required.
Complete all 15 questions below with 100% accuracy to finish this lesson. You must also complete the reflection above before submitting.
1. Measures of association differ from measures of statistical significance in that they:
2. In a cohort study, 150 of 2,000 exposed individuals and 75 of 2,000 non-exposed individuals develop the disease. What is the risk ratio?
3. The odds ratio can be calculated from a case-control study because:
4. RD = 0.043 in the smoking and low-birth-weight example means:
5. If RR = 4.0, the attributable fraction in the exposed (AFe) is:
6. Vaccine efficacy of 80% indicates:
7. A common risk factor with a modest RR may have a larger AFp than a rare risk factor with a high RR because:
8. PAR is best described as:
9. The null value for the risk ratio (RR) is:
10. A 95% CI for RR of (0.85, 1.32) suggests:
11. Confidence intervals for OR are asymmetric around the point estimate because:
12. In the formula var(ln OR) = 1/a1 + 1/a0 + 1/b1 + 1/b0, increasing all cell counts will:
13. Which of the following measures CANNOT be estimated from a case-control study, even with external data?
14. The Pearson χ² test is most appropriate when:
15. A study finds RR = 1.8 (P = 0.40). Which interpretation is most appropriate?
✦ Complete the final reflection above before submitting